
AndroLua解密
前言
AndroLua 是一个轻量的 Android Lua 运行环境,用来在安卓手机上直接运行 Lua 脚本。
常见实现主要有两种:
一种是基于 so 库 的方式,也就是 luajava.so。

另一种是基于 LuaJ 的 Java 实现(这种一般加密较少,因为 Java 层相对更容易逆向)。
AndroLua 体系里有非常多的改版,其中比较典型的是国内 泥人(nirenr) 的版本:
https://github.com/nirenr/AndroLua_pro
这个版本对 AndroLua 做了大幅改造,让 Lua 的性能和功能都有明显提升。不仅支持编写 Android 窗口程序,还对运行速度做了优化,并集成了很多常用模块,例如 import、http、bson、xml、socket、zlib 等,使调用更加方便。
不过后来泥人退坑,社区又 fork 出了 plus、plusplus 等版本,加密也逐渐开始出现。
接下来就来分析一些常见的 AndroLua 加密方式,并研究如何还原出原生 Lua 字节码。
AndLua解密
先来讲讲最常见的andlua加密
andlua不开源,使用androlua写的一个androlua编辑器包括打包源码分享等功能,貌似是nirenr编写 , 后续由狸猫🐱等人接手,主要用于编写外挂?
这个现在网上已经有很多工具来解密
https://www.luatool.cn/
也有文章分析过
https://blog.csdn.net/qq_39268483/article/details/124679327
这里我们来简单看一下分析过程
打开luajava.so
首先要找的是加载lua代码的函数
我们可以在网上找一下对应正常的androlua源码
https://github.com/WhiredPlanck/nirenr.AndroLua/blob/3193b00698b79601c54cae3c1fd3acc010473b1a/luajava/src/main/jni/lua/src/lauxlib.c#L780
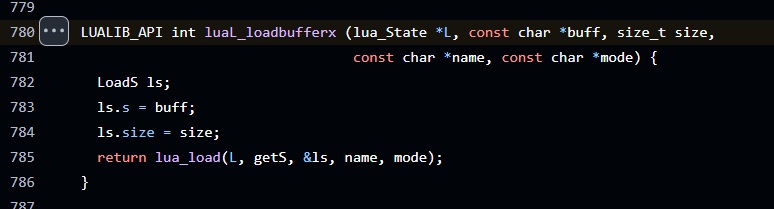
没错是luaL_loadbufferx
在ida中也找到对应的位置,可以导入一个lua结构体文件方便分析(在附件中给出了一份)
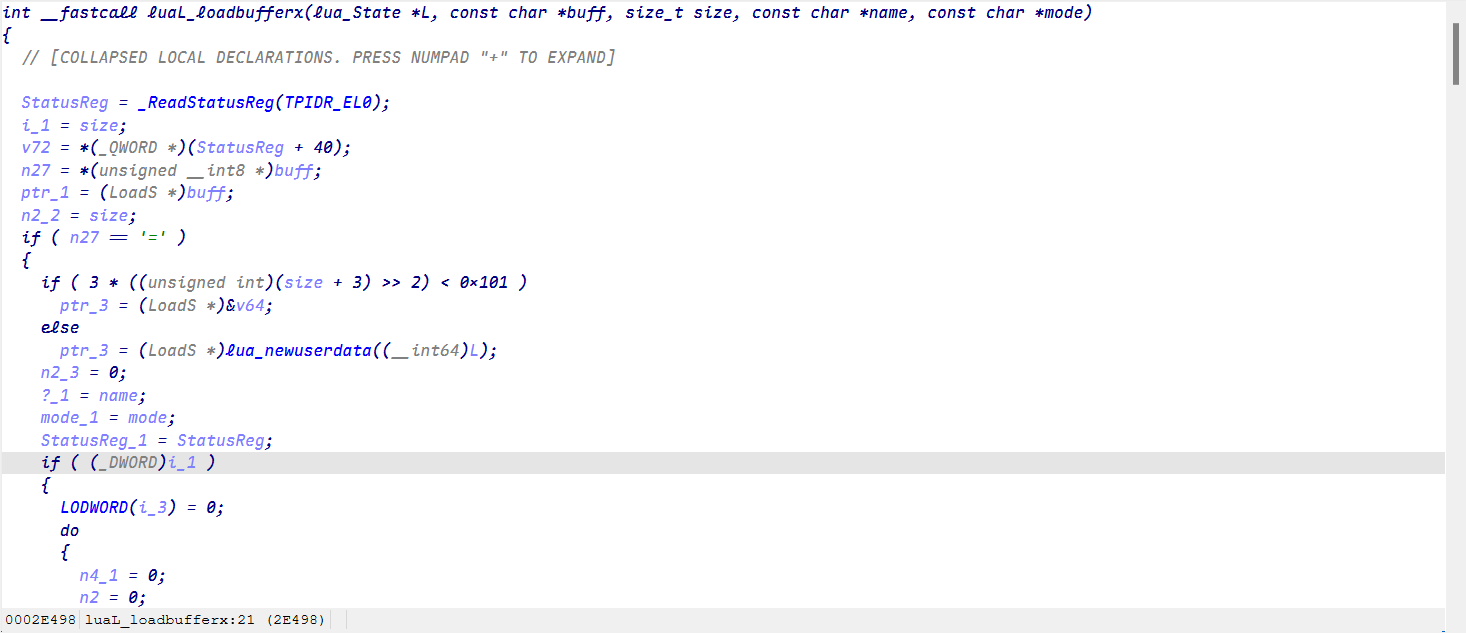
简单对比一下源码就发现加密就在此处,经过分析可以写脚本处理还原
import base64
import base64
import zlib
fp=open("main.lua","rb")
buffer=fp.read()
buffer=b'H'+buffer[1:]
buffer=base64.b64decode(buffer)
init=0
buffer_dec1=[]
for i in buffer:
init=init^i
buffer_dec1.append(init)
buffer_dec1=bytes(buffer_dec1)
buffer_dec2=b'\x78'+buffer_dec1[1:]
decompressed = zlib.decompress(buffer_dec2)
print(decompressed[0])
with open("main.lua_dec","wb") as f:
f.write(b'\x1b'+decompressed[1:])反编译!
什么?怎么字符串全是乱码
那一定在加载字符串的地方有魔改
我们同样可以在源码中发现LoadString函数
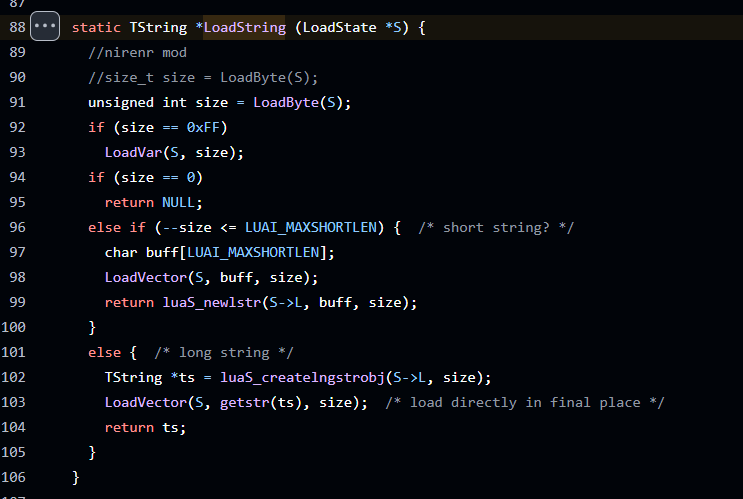
可恶在ida中符号被去除了
我们推到一下,首先它在LoadFunction被使用了
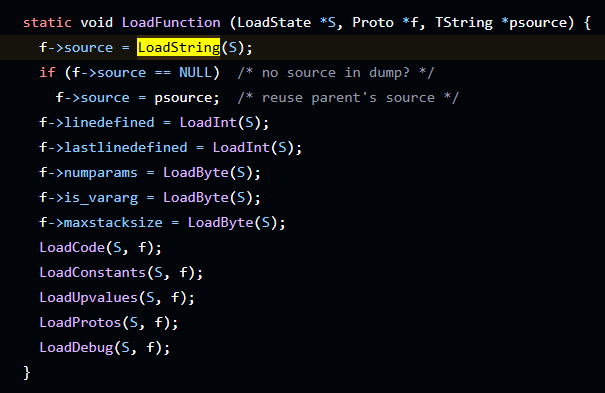
LoadFunction在luaU_undump中用到
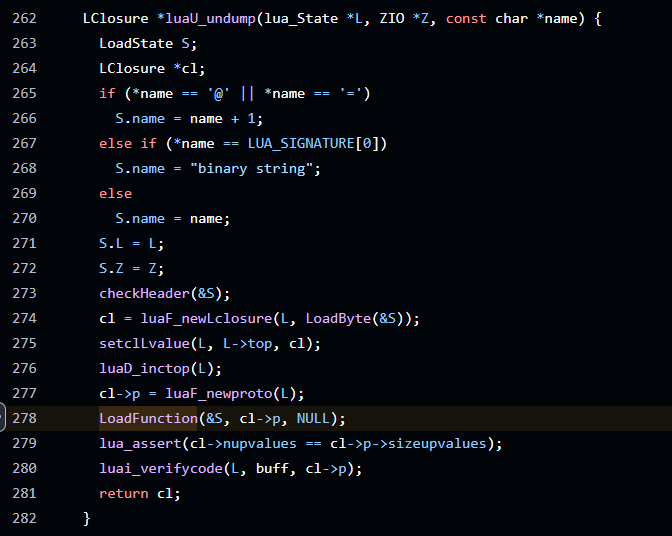
luaU_undump在f_parser中用到
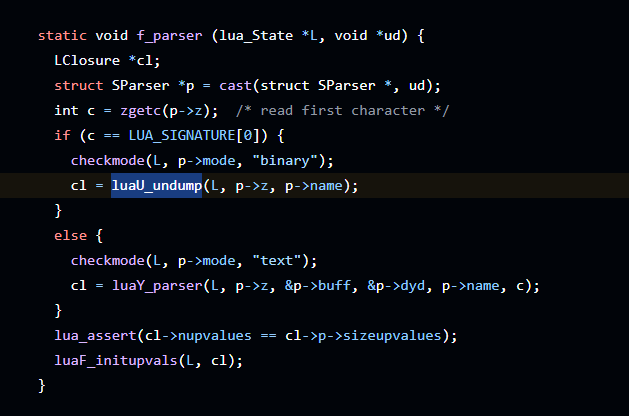
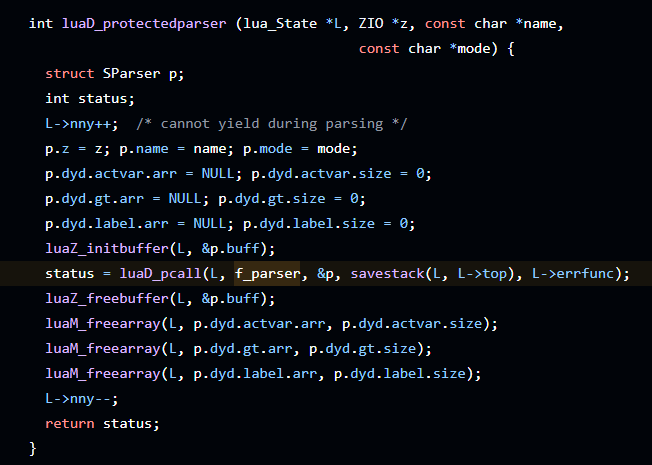
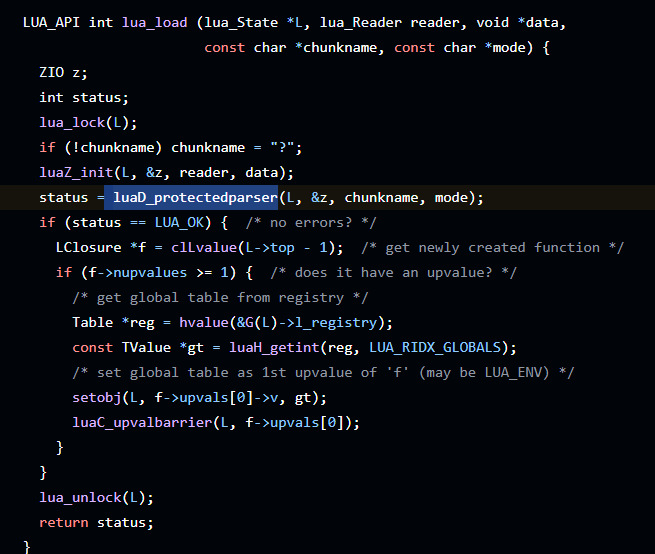
最终在lua_load中找到了(lua_load在ida中有符号的函数,其他都没有符号)
我们通过导入结构体和源码对比来逐一找到这些函数!
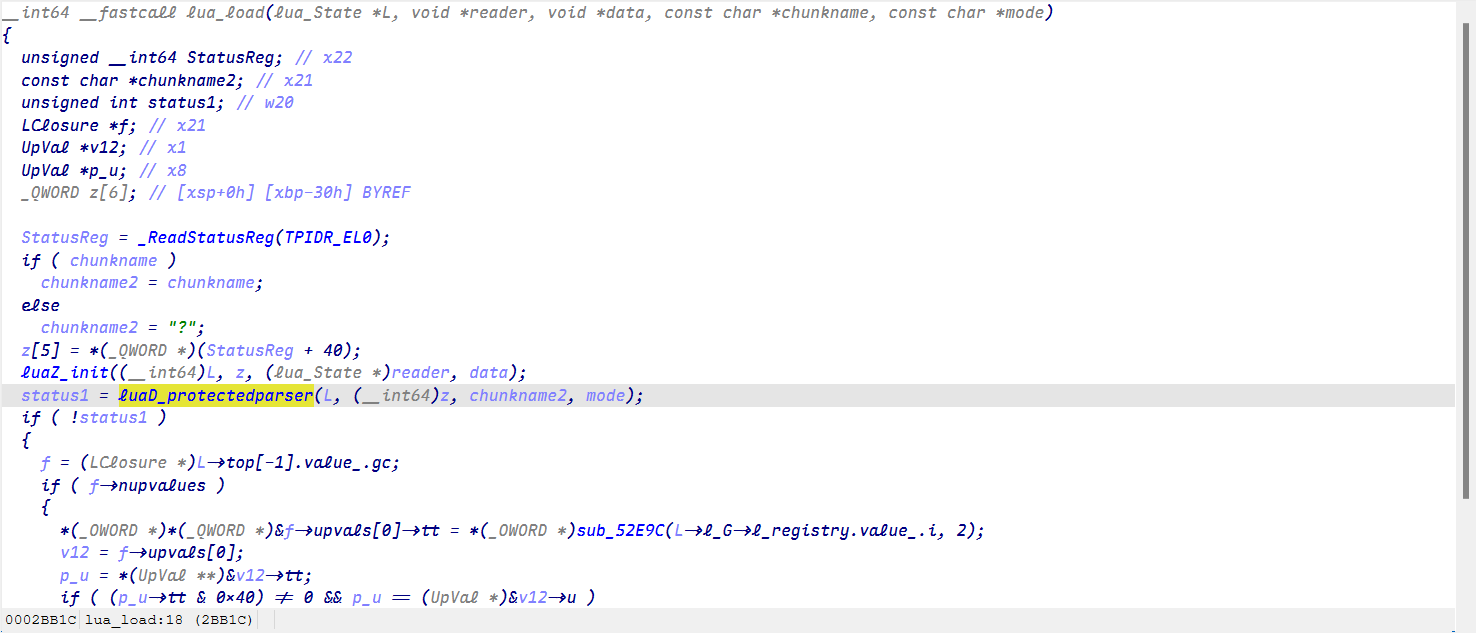
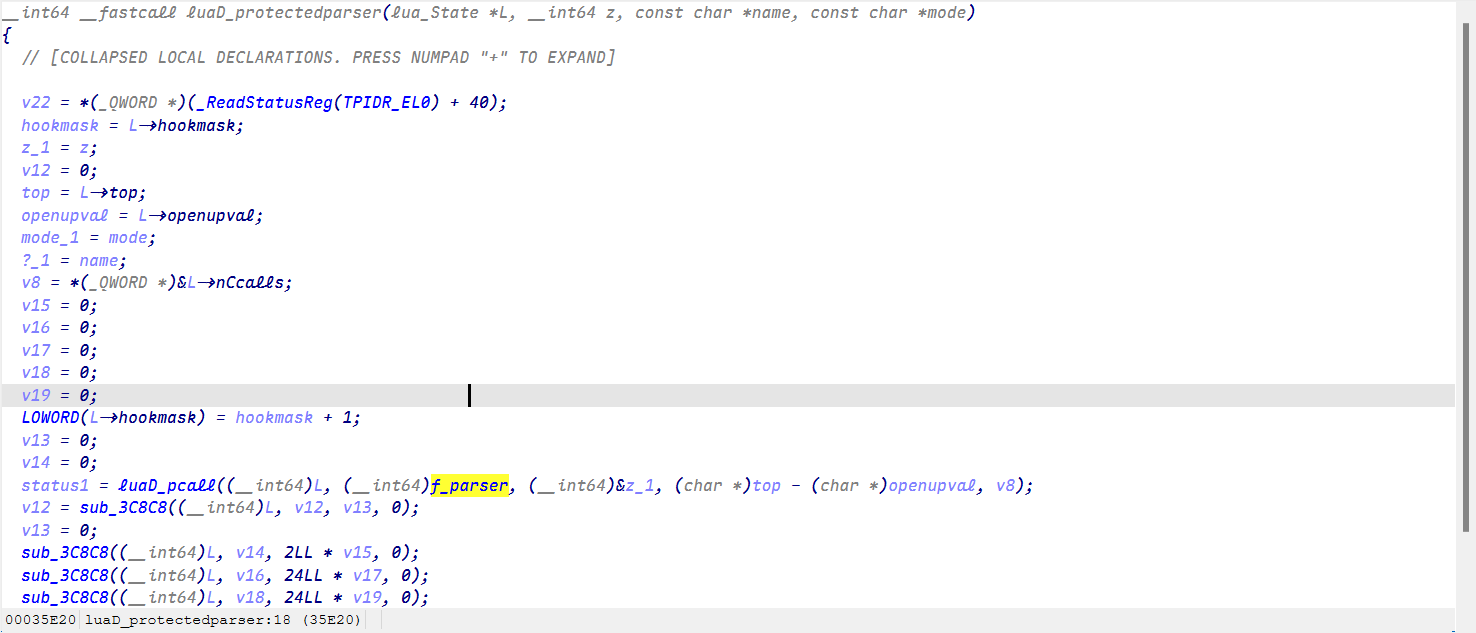
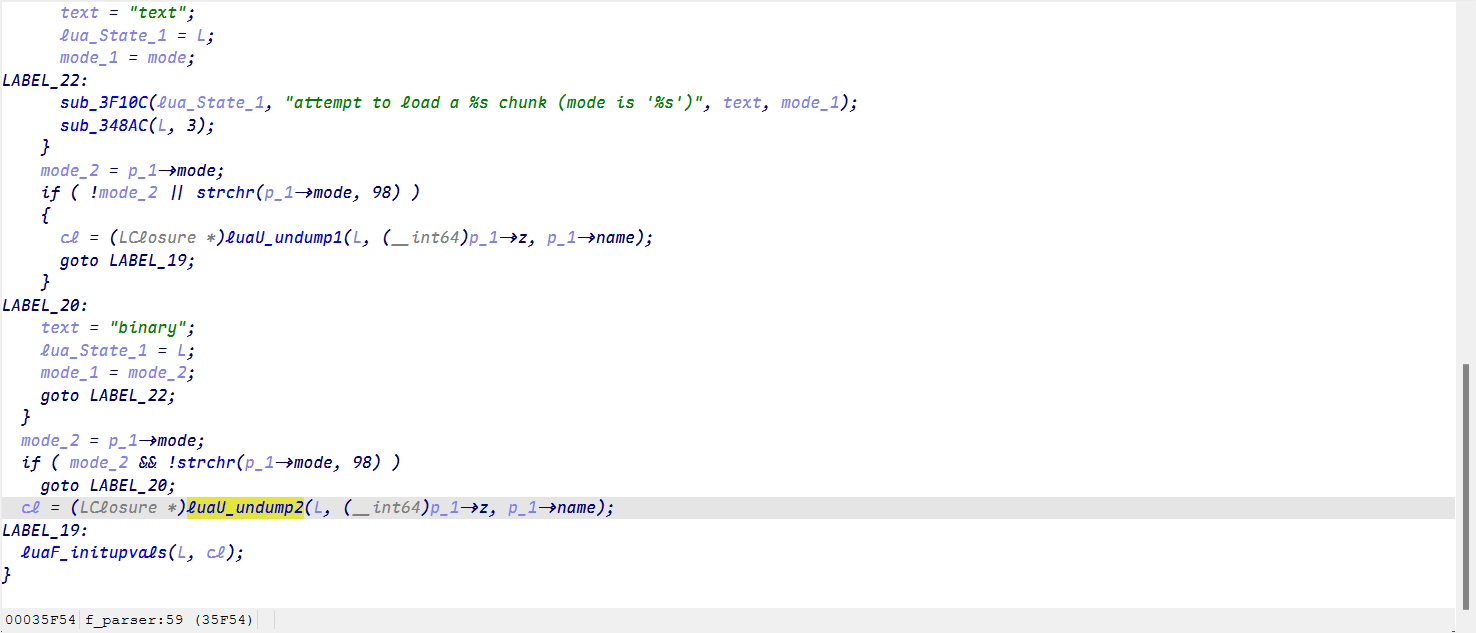
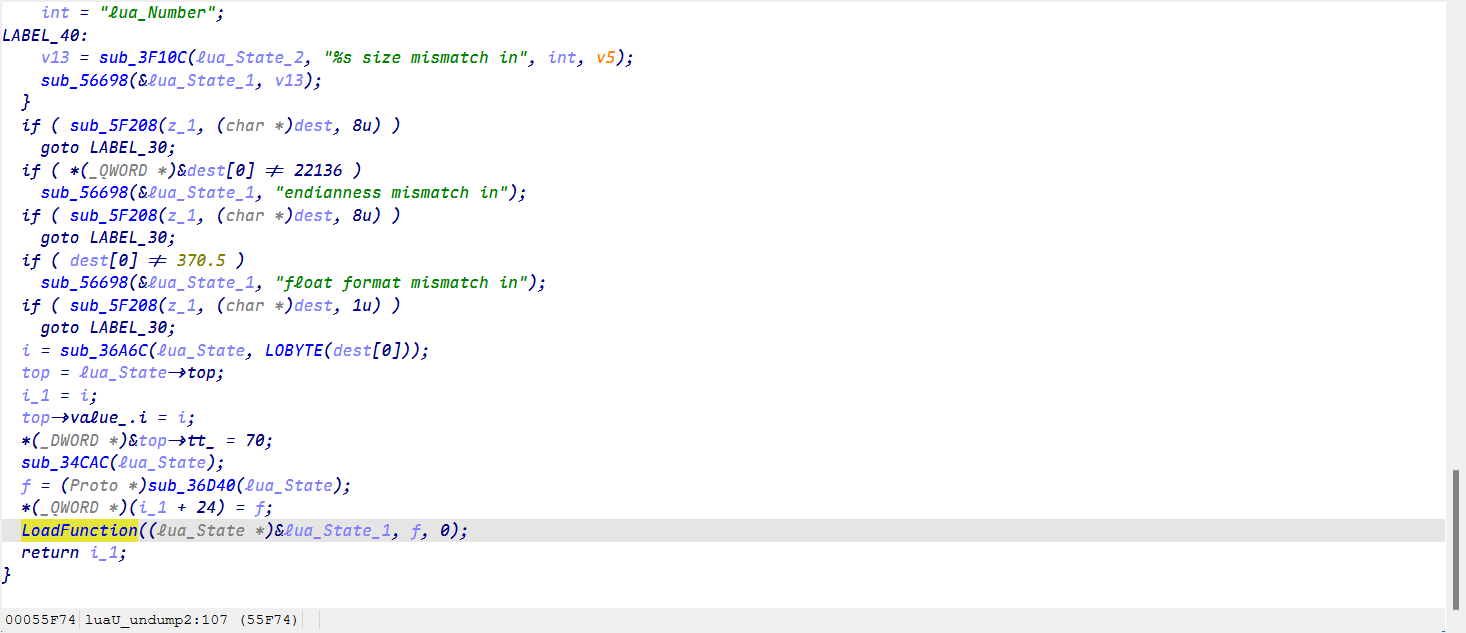
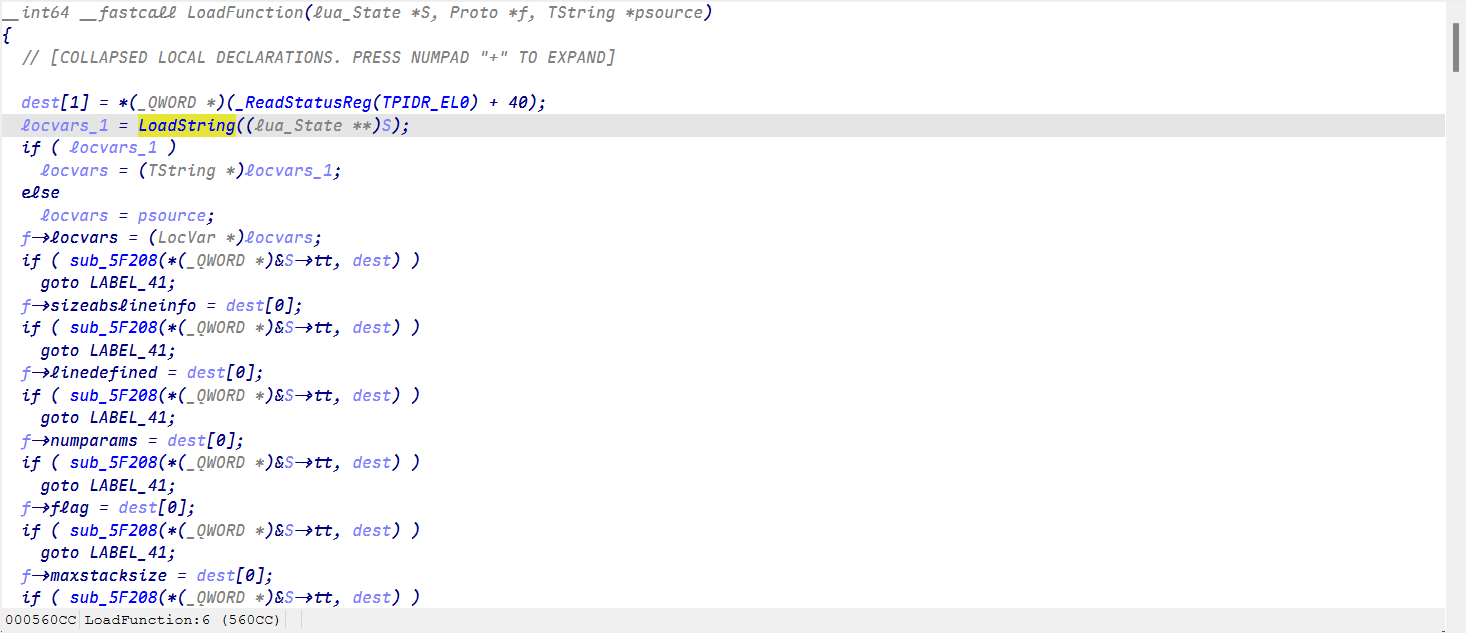
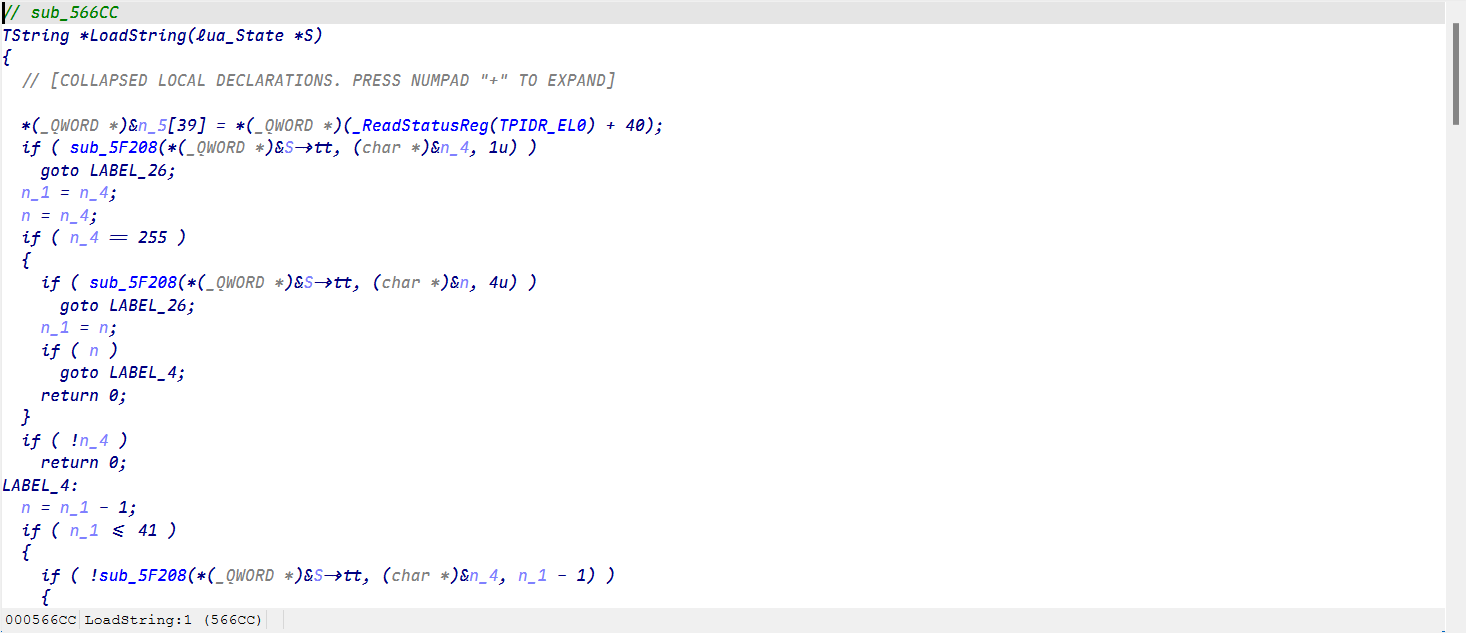
最终成功找到LoadString就可以分析它的加密了
这里我将脚本解密和字符串解密合成大脚本如下:
import base64
import zlib
import unicodedata
import os
# ==========================================
# 工具函数:字符串解密算法 (Layer 2 核心)
# ==========================================
def algo_decrypt_string(payload_bytes):
"""
int x=size-1;
int v5=b.charAt(0)^x;
"""
b = bytearray(payload_bytes)
size_minus_1 = len(b)
if size_minus_1 == 0:
return b
x = size_minus_1
v5 = b[0] ^ x
v6 = x + v5
for i in range(size_minus_1):
v8 = x % 255
x += v6
original_byte = b[i]
b[i] = original_byte ^ v8
return b
def is_valid_utf8_text(data_bytes):
"""
验证解密后的数据是否为合法的 UTF-8 文本
防止误伤非字符串的字节码指令
"""
if not data_bytes:
return True
try:
decoded_str = data_bytes.decode('utf-8')
except UnicodeDecodeError:
return False
# 检查控制字符,剔除乱码
for char in decoded_str:
if unicodedata.category(char) == 'Cc':
if char not in ('\r', '\n', '\t'):
return False
return True
# ==========================================
# 第一阶段:容器解密 (Base64 + XOR + Zlib)
# ==========================================
def stage1_loader_decrypt(filename):
print(f"[*] Stage 1: 正在读取并解压 {filename} ...")
if not os.path.exists(filename):
print(f"错误: 找不到文件 {filename}")
return None
with open(filename, "rb") as fp:
buffer = fp.read()
# 1. 修正头部并 Base64 解码
# buffer=b'H'+buffer[1:]
if len(buffer) > 0:
buffer = b'H' + buffer[1:]
try:
buffer = base64.b64decode(buffer)
except Exception as e:
print(f"Base64 解码失败: {e}")
return None
# 2. 滚动异或解密
# init=init^i 这种算法
init = 0
buffer_dec1 = bytearray()
for i in buffer:
init = init ^ i
buffer_dec1.append(init)
# 3. Zlib 解压
# buffer_dec2=b'\x78'+buffer_dec1[1:]
if len(buffer_dec1) > 1:
# 手动修复 zlib 头 (78 = Deflate)
buffer_dec2 = b'\x78' + buffer_dec1[1:]
try:
decompressed = zlib.decompress(buffer_dec2)
except zlib.error as e:
print(f"Zlib 解压失败: {e}")
return None
else:
print("数据过短,无法解压")
return None
# 4. 修正 Lua 头部
# f.write(b'\x1b'+decompressed[1:])
# 我们这里返回 bytearray 方便下一阶段直接在内存修改
if len(decompressed) > 0:
final_bytecode = bytearray(b'\x1b' + decompressed[1:])
return final_bytecode
return None
# ==========================================
# 第二阶段:字节码混淆修复 (String Deobfuscation)
# ==========================================
def stage2_bytecode_patch(data):
print(f"[*] Stage 2: 正在扫描并修复混淆字符串 (总大小: {len(data)} bytes)...")
length = len(data)
modified_count = 0
# 跳过 Lua 头部 (Signature + Header),防止误改配置信息
i = 0
if data.startswith(b'\x1bLua'):
i = 30
while i < length:
# 特征扫描: 04 (String Type in Lua 5.1)
if data[i] == 0x04:
if i + 1 >= length:
break
size_byte = data[i+1]
payload_len = size_byte - 1
# 长度合理性校验
if payload_len > 0 and (i + 2 + payload_len) <= length:
payload_start = i + 2
payload_end = payload_start + payload_len
original_payload = data[payload_start:payload_end]
# 尝试解密
decrypted_candidate = algo_decrypt_string(original_payload)
# 智能校验: 是否为有效文本 (支持中文)
if is_valid_utf8_text(decrypted_candidate):
# 打印预览
try:
dec_str = decrypted_candidate.decode('utf-8')
preview = dec_str if len(dec_str) < 25 else dec_str[:25] + "..."
# 仅在调试时取消下面注释,防止刷屏
# print(f" [Patch] Offset {i:04X}: '{preview}'")
except:
pass
# 应用修改
data[payload_start:payload_end] = decrypted_candidate
modified_count += 1
# 跳过已处理区域
i += 2 + payload_len
continue
i += 1
print(f"[*] Stage 2 完成: 共恢复了 {modified_count} 个字符串 (含中文)")
return data
# ==========================================
# 主程序
# ==========================================
if __name__ == "__main__":
input_file = "main.lua"
output_file = "main_decoded.lua"
# 1. 执行第一层解密
bytecode = stage1_loader_decrypt(input_file)
if bytecode:
# 2. 执行第二层解密 (无需保存中间文件,直接内存操作)
final_data = stage2_bytecode_patch(bytecode)
# 3. 保存最终结果
with open(output_file, "wb") as f:
f.write(final_data)
print(f"\n[Success] 所有操作完成!")
print(f"输出文件: {output_file}")
print("现在你可以尝试使用 luadec 反编译这个文件了。")这下再反编译就正常了!
LuaAppX Pro解密
分析完最常见的,我们再来看看一些他人魔改的加密是怎么样的
同样先找到luaL_loadbufferx函数
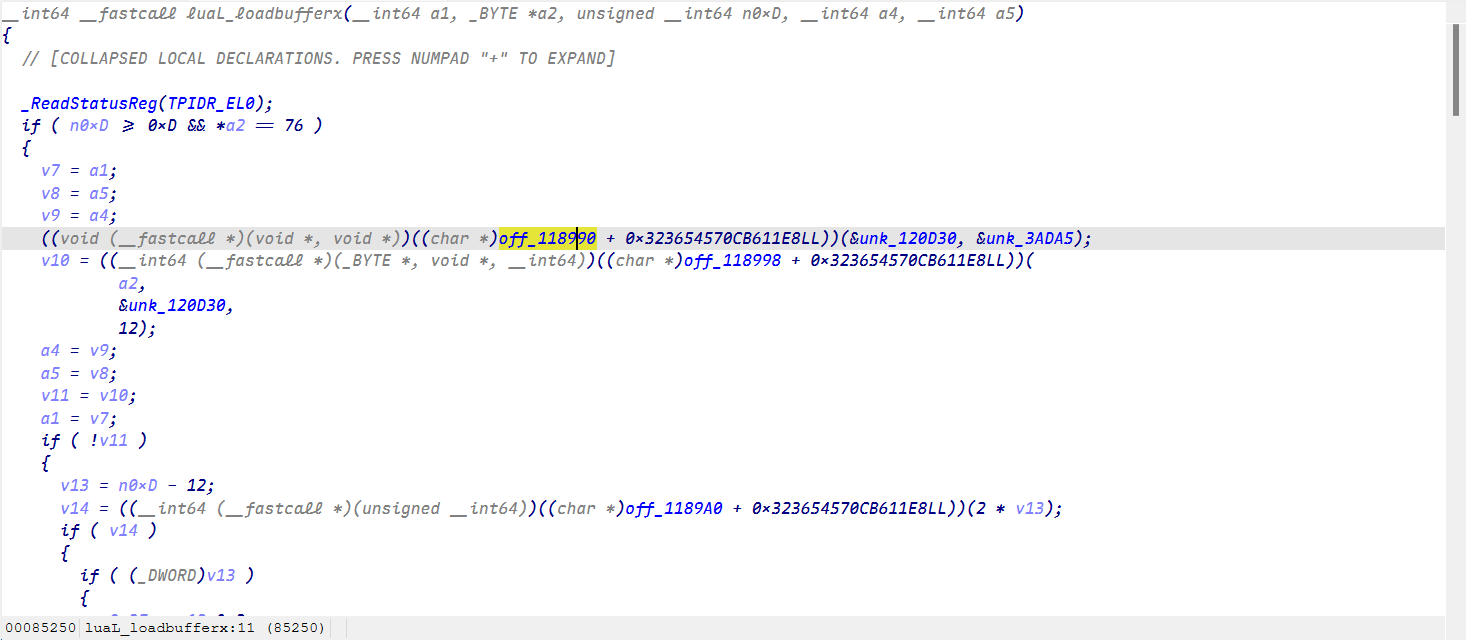
什么?函数都变成了超大的指针。
数据段也全部爆红
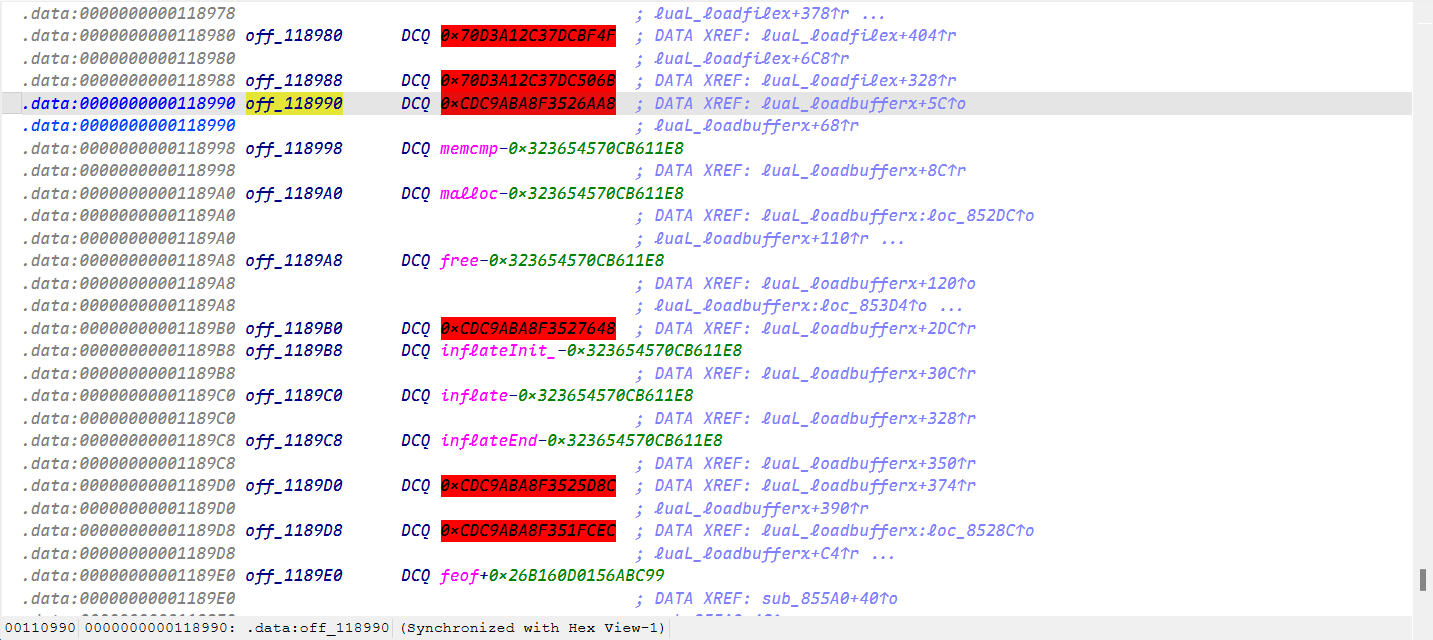
我们来分析其中一个


可以看到有两个大数相加,由于是64位整数,会有溢出
我们来简单模拟一下,可以看到真正的函数地址

这里我们通过一个ida脚本去除当前函数中的混淆
import idc
MAGIC_CONST = 0x323654570CB611E8
def apply_fix_and_patch():
# 你的数据范围
start_ea = 0x118990
end_ea = 0x1189D8 + 8
curr = start_ea
while curr < end_ea:
confused_val = idc.get_qword(curr)
# 计算真实地址 (64位溢出处理)
real_func_ptr = (confused_val + MAGIC_CONST) & 0xFFFFFFFFFFFFFFFF
# 获取函数名
name = idc.get_func_name(real_func_ptr)
if not name:
name = idc.get_name(real_func_ptr) # 尝试获取导出名
if name:
print(f"Patching {hex(curr)}: {hex(confused_val)} -> {hex(real_func_ptr)} ({name})")
# --- 核心操作 1: Patch 数据 ---
# 这一步会直接修改 IDA 数据库中的值
idc.patch_qword(curr, real_func_ptr)
# --- 核心操作 2: 设置重复注释 ---
idc.set_cmt(curr, f"Real Function: {name}", 1)
# --- 核心操作 3: 重命名该偏移量 ---
# 加上 ptr_ 前缀方便识别,例如 ptr_malloc
idc.set_name(curr, f"ptr_{name}", idc.SN_CHECK)
curr += 8
# 刷新分析
print("Done! Please press F5 to refresh decompiler.")
apply_fix_and_patch()可以看到已经成功分析出了函数(只不过后面有无意义的大数)
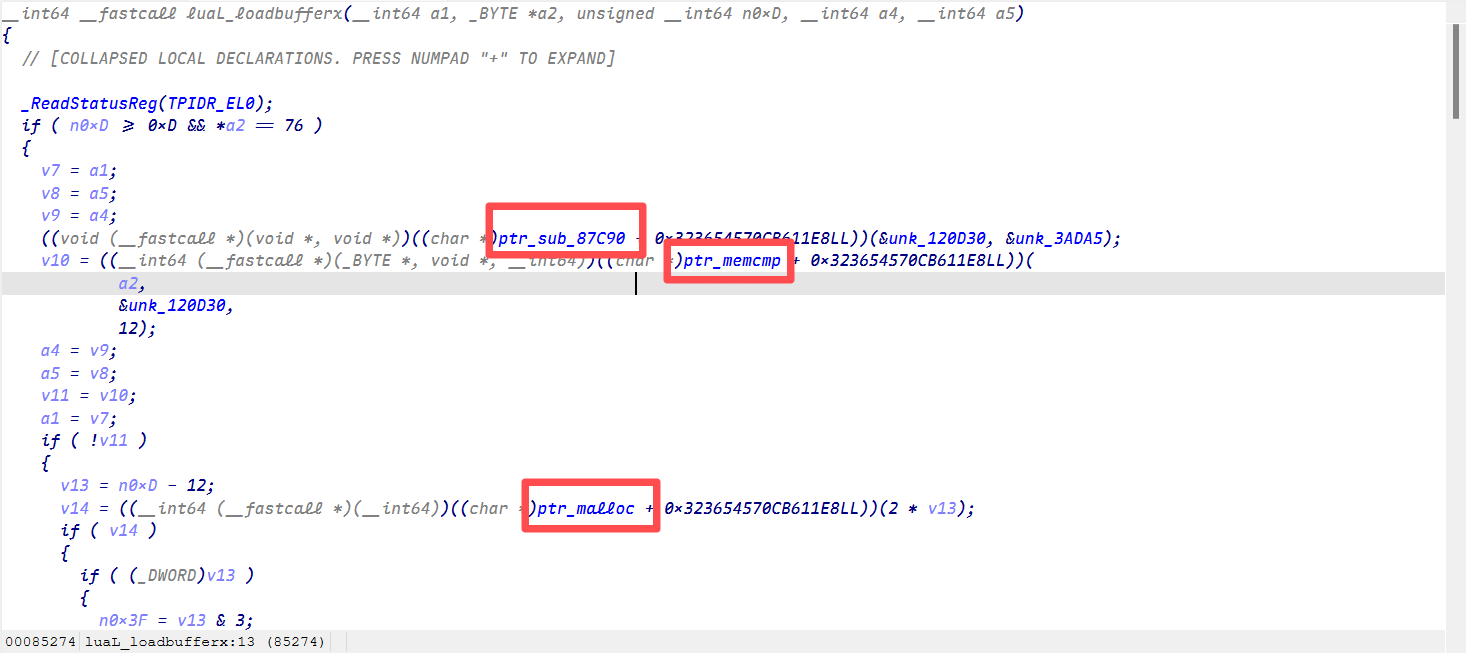
强大的gemini也写了个脚本来解决这个问题
import idc
import idautils
import ida_bytes
import ida_ua
def patch_arm64_magic_x26():
# 获取当前光标所在的函数范围
func = ida_funcs.get_func(idc.get_screen_ea())
if not func:
print("Error: Not inside a function.")
return
print(f"Scanning function at {hex(func.start_ea)}...")
# ARM64 机器码
# MOV X26, #0 => 0xD280001A
CODE_MOV_X26_ZERO = 0xD280001A
# NOP => 0xD503201F
CODE_NOP = 0xD503201F
# 需要匹配的魔数部分 (根据你提供的汇编)
# 0x3236 5457 0CB6 11E8
# 注意:MOVK 的 operand value 通常只返回立即数部分
MAGIC_PARTS = {
0x11E8: "BASE", # MOV X26, #0x11E8
0xCB6: "HIGH", # MOVK X26, #0xCB6, LSL#16
0x5457: "HIGH", # MOVK X26, #0x5457, LSL#32
0x3236: "HIGH" # MOVK X26, #0x3236, LSL#48
}
count = 0
# 遍历函数内的每一条指令
for ea in idautils.Heads(func.start_ea, func.end_ea):
# 1. 检查操作数 0 是否为 X26
# o_reg = 1, X26 的寄存器编号通常是 26+... 但用文本匹配最稳
op1_text = idc.print_operand(ea, 0)
if op1_text != "X26":
continue
# 2. 获取操作数 1 (立即数) 的值
# distinct=1 意味着获取原始值
imm_val = idc.get_operand_value(ea, 1)
# 3. 匹配魔数
if imm_val in MAGIC_PARTS:
mnem = idc.print_insn_mnem(ea)
action = MAGIC_PARTS[imm_val]
# 只有当助记符也匹配时才修改,防止误伤
if action == "BASE" and mnem == "MOV":
print(f"Patching BASE at {hex(ea)}: MOV X26, #0x11E8 -> MOV X26, #0")
idc.patch_dword(ea, CODE_MOV_X26_ZERO)
count += 1
elif action == "HIGH" and mnem == "MOVK":
print(f"Patching HIGH at {hex(ea)}: {mnem} ... -> NOP")
idc.patch_dword(ea, CODE_NOP)
count += 1
print(f"Done! Patched {count} instructions.")
print("Please press F5 to refresh the decompiler.")
patch_arm64_magic_x26()现在看就舒服多了
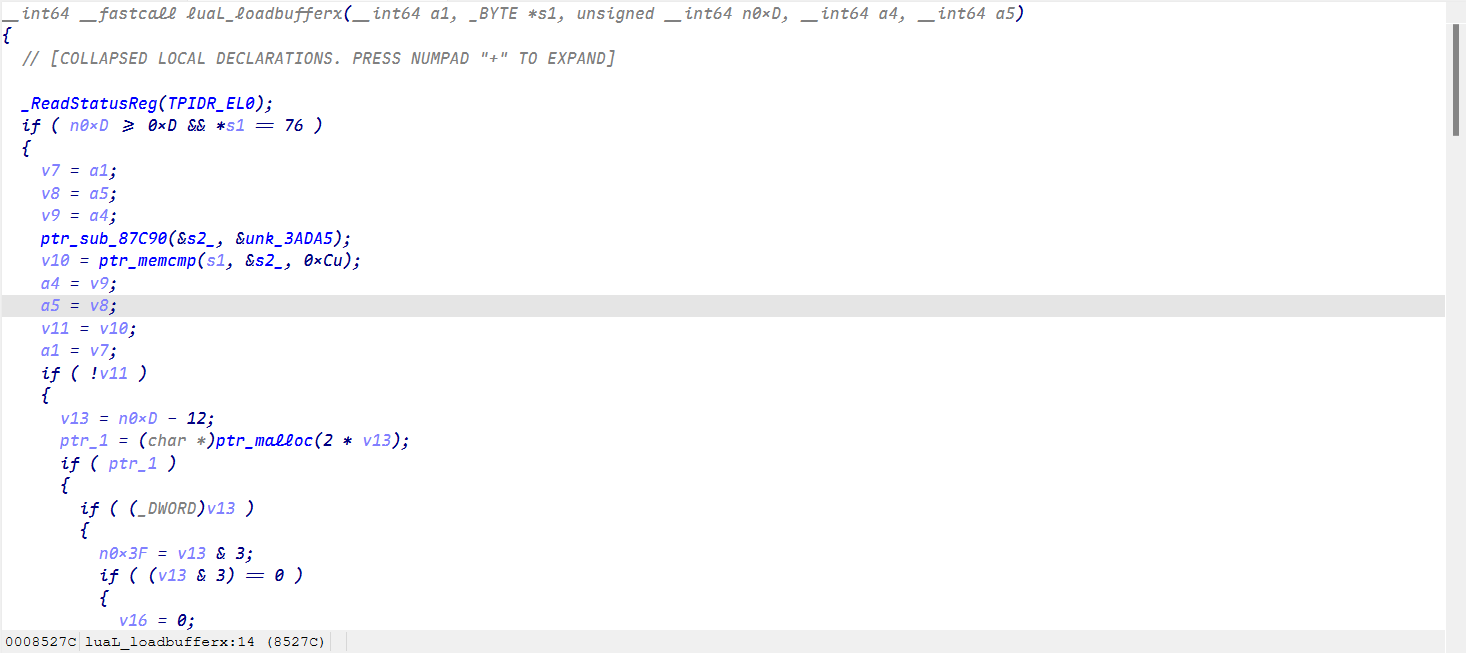
由于这个脚本开头开头都有明确的标志,也不难看出前面在判断和处理这个头部

中间和andlua类似在做base64,Zlib解码

在最后,出现真正的解密部分,伪 AES(虽然它执行了 AES 的密钥扩展,但在真正的加密循环中,它完全没有使用 AES 的 10 轮变换, 它只是做了一个简单的异或流加密)
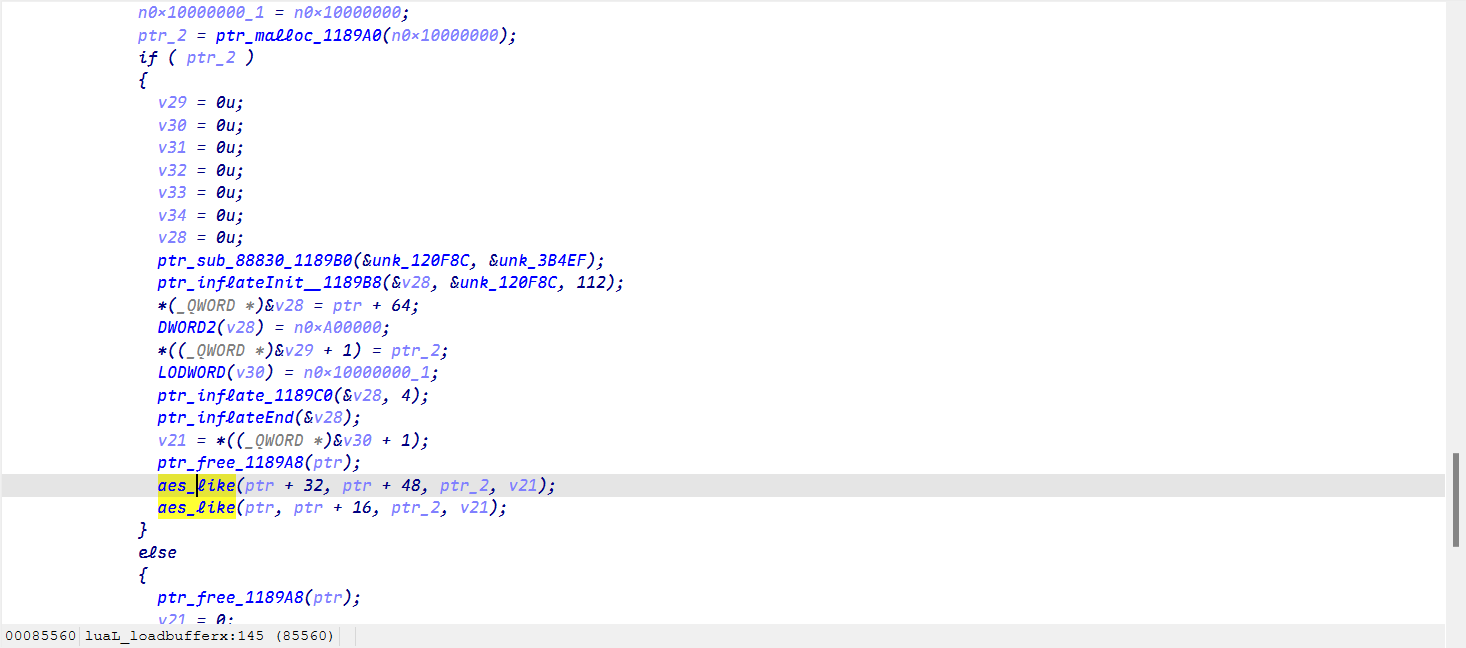
最终写出完整的解密脚本
该脚本仅供学习使用,请不要去解密他人luaappx pro软件,谢谢
import os
import base64
import zlib
import struct
# ================= 配置区域 =================
INPUT_FILE = "AboutActivity.lua"
OUTPUT_FILE = "decrypted.luac"
SIGNATURE = b"LuaAppX Pro="
# ===========================================
def xor_bytes(a, b):
"""两个 bytes 进行异或"""
return bytes(x ^ y for x, y in zip(a, b))
def inc_bytes_be(iv):
"""模拟 C 代码中的 128位 大端序自增"""
# 将 bytes 转为大整数
val = int.from_bytes(iv, byteorder='big')
val += 1
# 转回 bytes (16字节)
return val.to_bytes(16, byteorder='big')
def fake_aes_ctr_decrypt(data, key, iv):
"""
模拟 sub_86F74 的逻辑:
Keystream = Key ^ IV
Data = Data ^ Keystream
IV++
"""
out = bytearray()
curr_iv = iv
# 按 16 字节分块处理
for i in range(0, len(data), 16):
chunk = data[i : i+16]
# 核心算法:Keystream = Key XOR Current_IV
# 原文代码: v21 = veorq_s8(v34, v16); (v34是IV, v16是Key)
keystream_block = xor_bytes(key, curr_iv)
# 解密当前块
# 如果最后一块不足16字节,keystream截断使用
decrypted_chunk = xor_bytes(chunk, keystream_block[:len(chunk)])
out.extend(decrypted_chunk)
# IV 自增 (模拟 v29 = v28 + 1 ... 那段循环)
curr_iv = inc_bytes_be(curr_iv)
return bytes(out)
def main():
if not os.path.exists(INPUT_FILE):
print(f"File {INPUT_FILE} not found.")
return
print(f"[*] Reading {INPUT_FILE}...")
with open(INPUT_FILE, "rb") as f:
data = f.read()
# 1. Base64 Decode
b64_data = data[12:]
try:
decoded = base64.b64decode(b64_data)
print("[+] Base64 decoded.")
except Exception as e:
print(f"[!] Base64 error: {e}")
return
if len(decoded) < 64:
print("[!] Data too short.")
return
# 2. Extract Keys
key2, iv2 = decoded[0:16], decoded[16:32]
key1, iv1 = decoded[32:48], decoded[48:64]
# 3. Zlib Decompress
try:
payload = zlib.decompress(decoded[64:])
print(f"[+] Zlib decompressed. Size: {len(payload)}")
except:
try:
payload = zlib.decompress(decoded[64:], -15)
print(f"[+] Zlib (Raw) decompressed. Size: {len(payload)}")
except Exception as e:
print(f"[!] Zlib failed: {e}")
return
# 4. Decrypt (Fake AES CTR)
print("[*] Starting Fake AES-CTR Decryption...")
# 第一层解密 (Key1, IV1)
temp = fake_aes_ctr_decrypt(payload, key1, iv1)
# 第二层解密 (Key2, IV2)
final = fake_aes_ctr_decrypt(temp, key2, iv2)
# 5. Check Head
head = final[:4]
print(f"[*] Result Head: {head.hex()}")
# 标准 Lua 头: 1B 4C 75 61
# LuaJIT 头: 1B 4C 4A
if head.startswith(b'\x1bL'):
print("[SUCCESS] Found valid Lua header!")
else:
print("[WARNING] Header does not match standard Lua, but saving anyway.")
with open(OUTPUT_FILE, "wb") as f:
f.write(final)
print(f"[+] Saved to {OUTPUT_FILE}")
if __name__ == "__main__":
main()
附件
lua_structs.h
我总结的部分lua结构体头文件
https://bluestars.lanzouu.com/ibBlo3ib5fgj (注意后缀删掉.txt)
luajava.so
andlua的版本,没有符号
https://bluestars.lanzouu.com/iKzzh3ib5l2b (注意后缀删掉.zip)
luajava.i64
andlua的版本,我手动恢复了部分符号和结构体
https://bluestars.lanzouu.com/ifkqo3ib5lji (注意后缀删掉.zip)
LuaAppX Pro.apk
可能是最后一个版本,在assets可以看到加密的lua脚本,lib中提取luajava.so
https://bluestars.lanzouu.com/iB9723ib5moj